
Power Automateのクラウドフローでは、文字列の文字コードはUTF-8しか扱うことができません。
Shift_JISのファイルをPower Automateで何の工夫もせずに読み込むと文字化けしてしまいます。
UTF-8はほとんど世界標準と言っていいくらい定着していますが、未だにShift_JISでテキストファイルやCSVファイルをエクスポートするシステムも残っていたりします。
Power Automateで出力したUTF-8のファイルにBOMを付けてExcelで読み込めるようにする、Shift_JISのファイルを加工せずにコピーするなどの方法はいくつかのサイトで紹介されていますが、Shift_JISをクラウドフローだけで加工する方法はなかなか見当たりません。
今回はPower AutomateでShift_JISのテキストやCSVをどうしても扱わなくてはならないときの対処法について考えていきます。
本記事で紹介する対処法は、筆者独自の見解と検証に基づいています。
そのため、Power Automateやプログラミング言語のライブラリのサポートを受けるよりも、変換精度の信頼性が劣ります。
本記事の内容はあくまで参考程度にとどめていただき、実際の業務での使用は自己責任でお願いいたします。
本記事でご紹介した方法でデータの破損等が発生しても、当方では一切責任を負いかねます。
【結論】Power Automateの無料枠の範囲でShift_JISをUTF-8に変換する方法
今回はかなり話が長くなるので、先に結論として、作成したフローをお見せします。
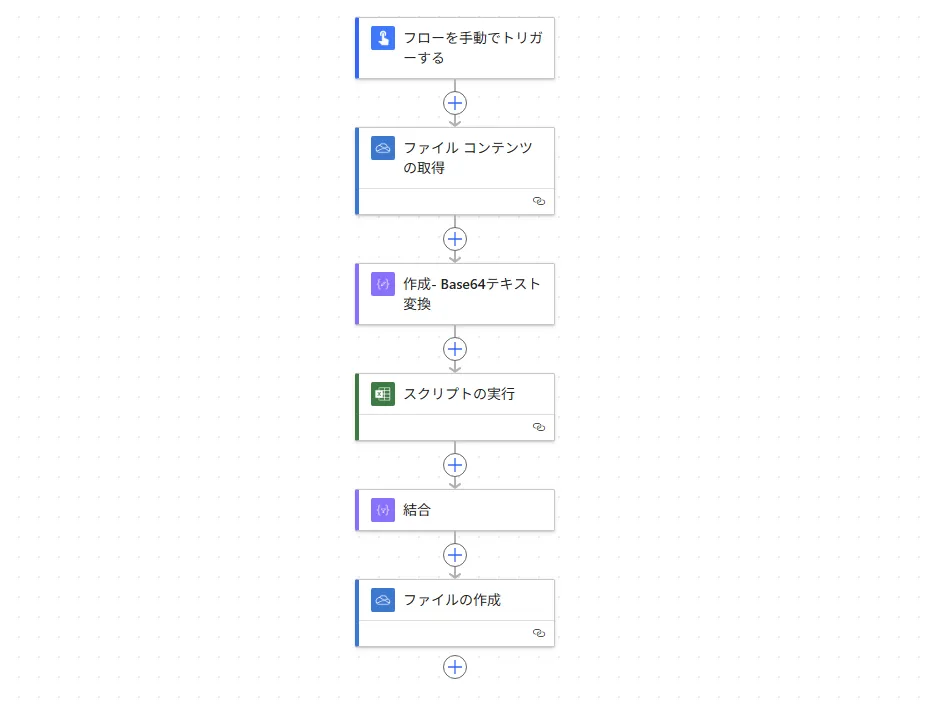
- SharePointやOneDriveからファイルを読み込む
- このとき、コンテンツタイプの推測は無効にする
- 取得したコンテンツに対して、作成アクションで
string関数とbase64関数をネストして、Base64の形状を保ったUTF-8文字列を作る - 2を、Shift_JISからUTF-8に変換するOfficeスクリプトに渡す
- 実行するブックは、あらかじめ作成しておいた「文字コード表.xlsx」にする(詳細はあとで解説します)
- OfficeスクリプトからUTF-8で変換して改行ごとに分割したUTF-8文字列の配列が返ってくる
- あとは好きなようにフローで取り扱う
Officeスクリプトのコードは以下です。
Shift_JIS → UTF-8変換 Officeスクリプト
/**
* Base64形式の文字列をShift_JISからUTF-8に変換し、CSVパース処理で行単位に分割する
* 文字コード表を使用してバイト値から文字を正確に変換
* @param base64String 変換するBase64文字列 (Shift-JIS CSV)
* @return UTF-8文字列の行の配列
*/
function main(workbook: ExcelScript.Workbook, base64String: string): string[] {
let sheet = workbook.getActiveWorksheet();
let codeTableSheet = workbook.getWorksheet("Shift_JIS文字コード表");
if (!codeTableSheet) {
sheet.getRange("A1").setValue("Error: Shift_JIS文字コード表が見つかりません");
return ["Error: Shift_JIS文字コード表が見つかりません"];
}
let codeTable = loadCodeTable(codeTableSheet);
let utf8Lines: string[] = [];
try {
// Base64をバイト配列に変換
let bytes = base64ToBytes(base64String);
// バイト配列をUTF-8文字列に変換
let utf8String = convertShiftJisToUtf8(bytes, codeTable);
// UTF-8文字列をCSV形式で行分割
let lines = parseCSVLines(utf8String);
// 結果を配列に格納
for (let i = 0; i < lines.length; i++) {
if (lines[i].trim() !== '') {
utf8Lines.push(lines[i]);
}
}
} catch (error) {
sheet.getRange("A1").setValue("Error: " + error.message);
return ["Error: " + error.message];
}
console.log(utf8Lines)
return utf8Lines;
}
/**
* 文字コード表ワークシートからコードマッピングを読み込む
* @param sheet 文字コード表ワークシート
* @return バイト値から文字へのマッピング
*/
function loadCodeTable(sheet: ExcelScript.Worksheet): Map<number, string> {
let codeTable = new Map<number, string>();
let usedRange = sheet.getUsedRange();
if (!usedRange) return codeTable;
let values = usedRange.getValues();
// ヘッダー行をスキップして2行目から開始
for (let i = 1; i < values.length; i++) {
let sjisDecimal = values[i][1]; // B列: Shift_JISバイト(10進)
let character = values[i][2]; // C列: 文字
if (typeof sjisDecimal === 'number' && typeof character === 'string') {
codeTable.set(sjisDecimal, character);
}
}
return codeTable;
}
/**
* Shift_JISバイト配列をUTF-8文字列に変換
* @param bytes Shift_JISバイト配列
* @param codeTable バイト値から文字へのマッピング
* @return UTF-8文字列
*/
function convertShiftJisToUtf8(bytes: Uint8Array, codeTable: Map<number, string>): string {
let result = '';
let i = 0;
while (i < bytes.length) {
let byte1 = bytes[i];
// 1バイト文字の判定 (ASCII + 半角カタカナ)
if ((byte1 >= 0x20 && byte1 <= 0x7E) || (byte1 >= 0xA1 && byte1 <= 0xDF)) {
// 1バイト文字として処理
let char = codeTable.get(byte1);
if (char) {
result += char;
} else {
// 文字コード表にない場合は直接ASCII変換を試行
if (byte1 >= 0x20 && byte1 <= 0x7E) {
result += String.fromCharCode(byte1);
} else {
// 不明な文字は ? で置換
result += '?';
}
}
i++;
}
// 2バイト文字の判定
else if (((byte1 >= 0x81 && byte1 <= 0x9F) || (byte1 >= 0xE0 && byte1 <= 0xFC)) &&
i + 1 < bytes.length) {
let byte2 = bytes[i + 1];
// 2バイト目が有効範囲内かチェック
if ((byte2 >= 0x40 && byte2 <= 0x7E) || (byte2 >= 0x80 && byte2 <= 0xFC)) {
// 2バイト値を10進数に変換
let twoByteValue = (byte1 << 8) | byte2;
let char = codeTable.get(twoByteValue);
if (char) {
result += char;
} else {
// 不明な文字は ? で置換
result += '?';
}
i += 2;
} else {
// 2バイト目が無効な場合は1バイトとして処理
result += '?';
i++;
}
} else {
// その他の制御文字など
if (byte1 === 0x0D) {
result += '\r';
} else if (byte1 === 0x0A) {
result += '\n';
} else if (byte1 === 0x09) {
result += '\t';
} else {
result += '?';
}
i++;
}
}
return result;
}
/**
* UTF-8文字列をCSV形式で行分割
* セル内改行(ダブルクォーテーションで囲まれた改行)に対応
* @param csvString CSV形式のUTF-8文字列
* @return 行の配列
*/
function parseCSVLines(csvString: string): string[] {
let lines: string[] = [];
let currentLine = '';
let inQuotes = false;
let i = 0;
while (i < csvString.length) {
let char = csvString[i];
if (char === '"') {
inQuotes = !inQuotes;
currentLine += char;
} else if (!inQuotes && char === '\r' && i + 1 < csvString.length && csvString[i + 1] === '\n') {
// クォーテーション外でCRLFを検出
lines.push(currentLine);
currentLine = '';
i++; // LFもスキップ
} else if (!inQuotes && char === '\n') {
// クォーテーション外でLFを検出
lines.push(currentLine);
currentLine = '';
} else {
// 通常の文字
currentLine += char;
}
i++;
}
// 最後の行を追加
if (currentLine !== '') {
lines.push(currentLine);
}
return lines;
}
/**
* Base64文字列をバイト配列に変換する
* @param base64 デコードするBase64文字列
* @return バイト配列(Uint8Array)
*/
function base64ToBytes(base64: string): Uint8Array {
// Base64文字セット
const chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/';
// パディングを削除
let str = base64.replace(/=+$/, '');
// 結果のバイト配列のサイズを計算
let outputLength = Math.floor(str.length * 3 / 4);
let output = new Uint8Array(outputLength);
// 4文字ごとに処理(Base64は4文字で3バイトを表現)
let p = 0; // 出力配列のインデックス
for (let i = 0; i < str.length; i += 4) {
// 入力の4文字をBase64インデックスに変換
let n1 = chars.indexOf(str[i]);
let n2 = chars.indexOf(str[i + 1]);
let n3 = (i + 2 < str.length) ? chars.indexOf(str[i + 2]) : 64; // パディングの場合は64
let n4 = (i + 3 < str.length) ? chars.indexOf(str[i + 3]) : 64; // パディングの場合は64
// 3バイトに変換して出力配列に格納
if (p < outputLength) output[p++] = (n1 << 2) | (n2 >> 4);
if (p < outputLength) output[p++] = ((n2 & 15) << 4) | (n3 >> 2);
if (p < outputLength) output[p++] = ((n3 & 3) << 6) | n4;
}
return output;
}なぜこのようなフローやコードになったのか、ここから先で解説していきます。
Power AutomateでShift_JISのテキストを読み込むと発生する現象
Power AutomateでSharePointやOneDriveなどでShift_JISなどのUTF-8でない文字列を含むファイルを読み込むと、暗黙的にbase64ToString関数を通してUTF-8でデコードされてしまい、文字が破損してしまいます。
互換性のために Unicode でエンコードされていないテキストを変換する – Azure Logic Apps | Microsoft Learn
これを防ぐためには、ファイルを読み込むアクションでコンテンツタイプの推測を無効にして、出力のContent-Type をoctet-streamにする必要があります。
こうすることで後続のアクションに渡しても暗黙的なデコードが行われず、データが破壊されずに済みます。
しかし、octet-streamの状態ではフロー内のアクションで文字列としての操作はできません。コンテンツ内容をコピー・移動させることはできますが、文字列の検索や修正を行うことはできません。
Power Automate でテキストファイルの文字化けを回避する | Japan Dynamics CRM & Power Platform Support Blog
一般的に推奨される対処法と問題点
デスクトップフローと連携する
Power Automate Desktopでは文字コードの変換することができます。
そのため、クラウドフローで読み取ったShift_JISをデスクトップフローで渡し、UTF-8に変換された文字列を再度受け取ろうというものです。
簡単ではありますが、
- Power Automateプレミアムプランが必要
- ローカルPCに縛られる
- クラウドフローの大きな強みである「人も物理PCも必要なく自動実行できる」という利点を損なう
という問題点もあります。
Azure Functionsを使う
Microsoft公式が推奨しているのはこのやり方です。
互換性のために Unicode でエンコードされていないテキストを変換する – Azure Logic Apps | Microsoft Learn
Microsoft Learnの例はC#ですが、他にもJavaやPythonに加え、Officeスクリプトでお馴染みのTypeScriptも使うことができます。
各言語ともパッケージやモジュールで文字コードの変換をサポートしています。
こちらにも問題点はあります。
- Power Automate プレミアムプランが必要
- HTTPコネクタ と カスタムコネクタのどちらもプレミアムプランが必須
- 実装難易度が高い
- PythonやJava、TypeScriptなどの高級言語に馴染みがない市民開発にとっては、実装難易度が急激に上がってしまう
私と意見としても、プレミアムプランに課金できるのであれば、Azure Functionsを使うのが安全かなと思います。
あらかじめUTF-8に変換してから格納してもらう

そもそもそのShift_JISのファイルを格納しているのが人であれば、メモ帳アプリでUTF-8に変換してから格納してもらうようにマニュアル化してしまうというのも手です。
とはいえ、こんなことをしてしまったら自動化も何もありませんし、ヒューマンエラーでShift_JISのまま格納してしまえば事故になります。
関係する要素を整理する
文字コードとは何か?
コンピューターの内部では、文字は数値として扱われます。この文字と数値の対応関係を定めたものが文字コードです。
なんでそんな関係を定めなくてはいけないのでしょうか?
大前提として、コンピュータの内部ではすべての情報を0と1でしか扱えません。
私たちが画面で見ている可読文字や画像、スピーカーから流れる音などはすべてコンピュータ内で0と1で処理した結果なんです。
コンピュータが処理する0と1と、私たちの知覚に入る情報の間に何らかの取り決めをしないと対話することができません。
この取り決めのうち、文字に関するものが文字コードになるわけです。
問題なのは、この対応表が複数種類あることです。
日本語でよく使われるのはUTF-8とShift_JISの2種類です。
例:「こんにちは」という文字列の場合
Shift-JIS:
こ: 0x82B1
ん: 0x82F1
に: 0x82C9
ち: 0x82BF
は: 0x82CD
UTF-8:
こ: 0xE3 0x81 0x93
ん: 0xE3 0x82 0x93
に: 0xE3 0x81 0xAB
ち: 0xE3 0x81 0xA1
は: 0xE3 0x81 0xAFこのように、同じ文字でも文字コードが違うと全く異なるバイト列になります。
そのため、Shift_JISで作成されたファイルをUTF-8として読み込むと文字化けが発生してしまうのです。
| 文字 | Shift_JISバイト | UTF-8として解釈 | 結果 |
|---|---|---|---|
| こ | 0x82 0xB1 | 不正なUTF-8シーケンス | �� |
| ん | 0x82 0xF1 | 0xF1が4バイト文字開始だが不完全 | �� |
| に | 0x82 0xC9 | 0xC9から2バイト文字として解釈 | ɂ |
| ち | 0x82 0xBF | 不正なUTF-8シーケンス | �� |
| は | 0x82 0xCD | 0xCDが2バイト文字開始だが不完全 | �� |
文字化けという事故を起こしているのは間違ったマニュアルを渡しているからです。コンピュータは与えられたマニュアル通りに、流れてきたデータを変換しているに過ぎません。
文字コードが違っても変換を行わければ本質的に存在するのはバイナリデータでしかないともいえます。
Base64とは何か?
Base64は、バイナリデータを64種類の文字(A-Z、a-z、0-9、+、/)とパディング(=)で表現するエンコーディング方式です。
もともとはメール送信のために考案されたものですが、現在ではJSONでバイナリデータを送信たり、HTMLで画像を埋め込んだりなど、いろいろな場面でバイナリデータを扱うために使用されています。
Power AutomateではUTF-8以外の文字を格納しているファイルや、画像、PDFなど、ネイティブでサポートされていないファイルはBase64にエンコードされた状態で読み込まれます。
変換工程は主題ではないので深堀りはしませんが、バイナリを6ビットに分割し、インデックス番号に対応するBase64文字に置き換えていくのが、Base64のエンコード方法です。
例として、「こん」のShift_JIS文字コードをBase64に変換する工程を示します。
元データ: "こん" (0x82 0xB1 0x82 0xF1)
バイナリ: 10000010 10110001 10000010 11110001
6ビット分割: 100000 101011 000110 000010 111100 01????
パディング追加: 100000 101011 000110 000010 111100 010000
Base64: g r G C 8 Q
実際のBase64: "grGC8Q=="Power Automate内でのBase64の扱い
SharePointやOneDriveからファイルを読み込む際、Power Automateは以下の処理を自動で行います。
- ファイルの拡張子やヘッダー情報からコンテンツタイプを推測
- テキストファイル(
text/csvやtext/plain)と判断された場合、UTF-8として文字列変換を実行 - バイナリファイルの場合は、
application/octet-streamとして扱う
この自動判別機能により、Shift_JISのCSVファイルが「テキストファイル」と判断されてしまうと、Power Automateが勝手にUTF-8変換を行い、文字化けが発生します。
自動変換させたくない場合は、「ファイルコンテンツの取得」アクションのオプションである「コンテンツタイプの推測」をオフにします。そうすると、データはすべてcontent-typeがapplication\octet-streamのBase64で取得されます。
ここまではいいんです。
デバッグ画面の出力ではBase64は文字列して取得されていそうに見えますが、私たちの目に写っている字面の文字列としては扱えません。あくまで詳細不明なObject型として扱われます。
String型をパラメータとして受け取るアクションや関数に渡すとエラーになりますし、

Excelの書き込みアクションやスクリプトの引数として渡すと、暗黙的にbase64ToStringによる型変換が行われ、文字化けしたデータがExcelに渡ってしまいます。

また、ファイルの作成等でフローの外にデータを保存するアクションでは、当たり前ですがバイナリデータに変換されて送信されます。やはりBase64の形状を保った文字列にはなりません。
OfficeスクリプトでatobとTextDecoderを使いたい
JavaScriptでは以下のような標準APIがあり、これを使えばBase64をShift_JISの文字列を取得できそうです。
Window.atob()- Base64でエンコードされたデータの文字列をデコードする。
TextDecoder.decode()- 引数として渡されたバッファーからデコードしたテキストを含む文字列を返す。
function main(workbook: ExcelScript.Workbook, base64String: string) {
try {
// Base64文字列をバイナリデータにデコード
const binaryString = atob(base64String);
// バイナリ文字列をUint8Arrayに変換
const bytes = new Uint8Array(binaryString.length);
for (let i = 0; i < binaryString.length; i++) {
bytes[i] = binaryString.charCodeAt(i);
}
// TextDecoderを使ってShift_JISとしてデコード
const decoder = new TextDecoder('shift_jis');
const decodedText = decoder.decode(bytes);
console.log("Shift_JISデコード結果:", decodedText);
// 結果を返す
return decodedText;
} catch (error) {
console.log("Base64デコードエラー:", error);
return null;
}
}デスクトップ版のExcelで上記のスクリプトを作成し、テストしたところ正常に文字が変換されました。

なんとかBase64のままOfficeスクリプトに渡したい
しかし、Excelにそのまま渡すとBase64のままにならず、勝手にデコードをかけて文字化けさせてしまいます。
なんとかしてBase64の字面のまま、Officeスクリプトにデータを渡さなくてはなりません。
試行錯誤の末、以下のやり方でBase64の字面を保ったString型を作ることに成功しました。
string(base64(body('ファイル_コンテンツの取得')))ぶっちゃけなんでこれでBase64の字面を保ったString型が作れたのか、自分でもよくわかっていません💦
base64()が引数で受け取ったファイルコンテンツのBase64文字列を再エンコードし、string()がBase64を1回だけデコードして、結果的にbody('ファイル_コンテンツの取得')のBase64をString型として保持した、ということなんでしょうか。ただ、string()をbase64ToString()に変えると2回デコードされて文字化けしちゃうんですよね。このあたりの挙動は謎です。
PAから呼び出すOfficeスクリプトの制限
これでBase64の字面を保ったStringを作ったことで、OfficeスクリプトにBase64のまま渡せるように一件落着……
とはなりませんでしたorz
Power AutomateからOfficeスクリプトを呼び出すときの制限として、一部のWeb APIを呼び出すことができないようです。
Excel上では問題なく機能しても、PAから呼び出すと”atob is not defined.”いうエラーメッセージが返ってきてしまいます。TextDecoderの方もダメです。

\(^o^)/オワタ
自力でBase64→バイトデータ→UTF-8文字列の変換ロジックを作る
既存の関数が呼び出せないなら自分で実装するしかありません。
- Base64 → バイトデータ: Base64文字列を元のバイトデータに復元
- バイトデータ → 文字: Shift_JISのバイト値を対応する文字に変換
- 文字列組み立て: 変換された文字を順番に結合してUTF-8文字列を構築
という一連の処理を、Officeスクリプトで自作します。
文字コード表を作る
ます、Shift_JISのバイト値と対応する文字の対照表をExcelブック上に生成します。
Officeスクリプトをデスクトップアプリ上で、考えられる文字コードをすべてループ処理にかけて、TextDecoder関数とString.fromCharCode関数でShift_JISのバイト列と表示する文字を特定していき、結果をExcelブックに順番に書き込んでいく流れです。
function main(workbook: ExcelScript.Workbook) {
// 新しいワークシートを作成または既存のシートを取得
let worksheet = workbook.getWorksheet("Shift_JIS文字コード表");
if (!worksheet) {
worksheet = workbook.addWorksheet("Shift_JIS文字コード表");
}
worksheet.getUsedRange()?.clear();
// ヘッダーを設定
worksheet.getCell(0, 0).setValue("Shift_JISバイト(16進)");
worksheet.getCell(0, 1).setValue("Shift_JISバイト(10進)");
worksheet.getCell(0, 2).setValue("文字");
worksheet.getCell(0, 3).setValue("Unicode(16進)");
worksheet.getCell(0, 4).setValue("文字分類");
// ヘッダーのスタイルを設定
let headerRange = worksheet.getRange("A1:E1");
headerRange.getFormat().getFill().setColor("#4472C4");
headerRange.getFormat().getFont().setColor("white");
headerRange.getFormat().getFont().setBold(true);
let row = 1;
// 1バイト文字: ASCII文字 (0x20-0x7E)
console.log("ASCII文字を処理中...");
for (let sjis = 0x20; sjis <= 0x7E; sjis++) {
let char = String.fromCharCode(sjis);
worksheet.getCell(row, 0).setValue("0x" + sjis.toString(16).toUpperCase().padStart(2, '0'));
worksheet.getCell(row, 1).setValue(sjis);
worksheet.getCell(row, 2).setValue(char);
worksheet.getCell(row, 3).setValue("0x" + sjis.toString(16).toUpperCase().padStart(4, '0'));
worksheet.getCell(row, 4).setValue(getCharDescription(char, sjis));
row++;
}
// 1バイト文字: 半角カタカナ (0xA1-0xDF)
console.log("半角カタカナを処理中...");
for (let sjis = 0xA1; sjis <= 0xDF; sjis++) {
let unicode = sjis - 0xA1 + 0xFF61;
let char = String.fromCharCode(unicode);
worksheet.getCell(row, 0).setValue("0x" + sjis.toString(16).toUpperCase());
worksheet.getCell(row, 1).setValue(sjis);
worksheet.getCell(row, 2).setValue(char);
worksheet.getCell(row, 3).setValue("0x" + unicode.toString(16).toUpperCase());
worksheet.getCell(row, 4).setValue("半角カタカナ");
row++;
}
// 2バイト文字の処理
console.log("2バイト文字を処理中...");
// Shift_JIS 2バイト文字の範囲
let sjisRanges = [
// 第1バイトが0x81-0x9F
{ firstStart: 0x81, firstEnd: 0x9F, secondStart: 0x40, secondEnd: 0xFC },
// 第1バイトが0xE0-0xFC
{ firstStart: 0xE0, firstEnd: 0xFC, secondStart: 0x40, secondEnd: 0xFC }
];
for (let range of sjisRanges) {
for (let first = range.firstStart; first <= range.firstEnd; first++) {
for (let second = range.secondStart; second <= range.secondEnd; second++) {
// 0x7F は使用しない
if (second === 0x7F) continue;
try {
// Shift_JISバイト配列を作成
let sjisBytes = new Uint8Array([first, second]);
// TextDecoderでShift_JISからUnicodeに変換を試行
let decoder = new TextDecoder('shift_jis', { fatal: true });
let char = decoder.decode(sjisBytes);
// 有効な文字が得られた場合
if (char && char.length > 0 && char !== '�') {
let unicode = char.charCodeAt(0);
let sjisHex = "0x" + first.toString(16).toUpperCase().padStart(2, '0') +
second.toString(16).toUpperCase().padStart(2, '0');
let sjisDecimal = (first << 8) | second;
worksheet.getCell(row, 0).setValue(sjisHex);
worksheet.getCell(row, 1).setValue(sjisDecimal);
worksheet.getCell(row, 2).setValue(char);
worksheet.getCell(row, 3).setValue("0x" + unicode.toString(16).toUpperCase().padStart(4, '0'));
worksheet.getCell(row, 4).setValue(getUnicodeCharType(unicode));
row++;
// 進捗表示(1000文字ごと)
if ((row - 1) % 1000 === 0) {
console.log(`処理済み: ${row - 1}文字`);
}
}
} catch (e) {
// デコードエラーの場合はスキップ
}
}
}
}
worksheet.getRange("A:E").getFormat().autofitColumns();
// フィルターを追加
let dataRange = worksheet.getRange("A1:E" + (row - 1));
worksheet.getAutoFilter().apply(dataRange);
console.log(`Shift_JIS文字コード表を作成しました。合計${row - 1}文字を処理しました。`);
}
// ASCII文字の説明を取得する補助関数
function getCharDescription(char: string, code: number): string {
if (code >= 0x20 && code <= 0x2F) return "記号・句読点";
if (code >= 0x30 && code <= 0x39) return "数字";
if (code >= 0x3A && code <= 0x40) return "記号";
if (code >= 0x41 && code <= 0x5A) return "大文字アルファベット";
if (code >= 0x5B && code <= 0x60) return "記号";
if (code >= 0x61 && code <= 0x7A) return "小文字アルファベット";
if (code >= 0x7B && code <= 0x7E) return "記号";
return "ASCII文字";
}
// Unicode文字種別を判定する補助関数
function getUnicodeCharType(unicode: number): string {
if (unicode >= 0x3000 && unicode <= 0x303F) return "CJK記号・句読点";
if (unicode >= 0x3040 && unicode <= 0x309F) return "ひらがな";
if (unicode >= 0x30A0 && unicode <= 0x30FF) return "カタカナ";
if (unicode >= 0x3100 && unicode <= 0x312F) return "注音記号";
if (unicode >= 0x3200 && unicode <= 0x32FF) return "囲みCJK文字・月";
if (unicode >= 0x3300 && unicode <= 0x33FF) return "CJK互換文字";
if (unicode >= 0x4E00 && unicode <= 0x9FFF) return "CJK統合漢字";
if (unicode >= 0xFF00 && unicode <= 0xFF60) return "全角ASCII・記号";
if (unicode >= 0xFF61 && unicode <= 0xFF9F) return "半角カタカナ";
if (unicode >= 0xFFA0 && unicode <= 0xFFEF) return "半角ハングル";
if (unicode >= 0x2000 && unicode <= 0x206F) return "一般句読点";
if (unicode >= 0x2100 && unicode <= 0x214F) return "文字様記号";
if (unicode >= 0x2190 && unicode <= 0x21FF) return "矢印";
if (unicode >= 0x2200 && unicode <= 0x22FF) return "数学記号";
if (unicode >= 0x2300 && unicode <= 0x23FF) return "その他技術記号";
if (unicode >= 0x2500 && unicode <= 0x257F) return "罫線素片";
if (unicode >= 0x2580 && unicode <= 0x259F) return "ブロック要素";
if (unicode >= 0x25A0 && unicode <= 0x25FF) return "幾何学図形";
if (unicode >= 0x2600 && unicode <= 0x26FF) return "その他記号";
return "その他";
}このスクリプトにより、約6,000文字程度のShift_JIS文字コード表が生成されます。
Power Automateから呼び出すスクリプトを作る
今度は作成した文字コード表を使い、実際に文字コードの変換を行うスクリプトを作ります。
Base64デコード関数を実装
Power Automateから渡されるBase64文字列を元のバイトデータに復元する関数を実装します。
function base64ToBytes(base64: string): Uint8Array {
const chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/';
// パディング文字を除去
let str = base64.replace(/=+$/, '');
// 出力サイズの計算(Base64の4文字で3バイトを表現)
let outputLength = Math.floor(str.length * 3 / 4);
let output = new Uint8Array(outputLength);
let p = 0;
for (let i = 0; i < str.length; i += 4) {
// Base64文字をインデックスに変換
let n1 = chars.indexOf(str[i]);
let n2 = chars.indexOf(str[i + 1]);
let n3 = (i + 2 < str.length) ? chars.indexOf(str[i + 2]) : 64;
let n4 = (i + 3 < str.length) ? chars.indexOf(str[i + 3]) : 64;
// 3バイトに復元
if (p < outputLength) output[p++] = (n1 << 2) | (n2 >> 4);
if (p < outputLength) output[p++] = ((n2 & 15) << 4) | (n3 >> 2);
if (p < outputLength) output[p++] = ((n3 & 3) << 6) | n4;
}
return output;
}Shift_JISのバイト列を文字コード表から検索する関数を実装
変換されたバイト列を解析していきます。
- 0x20~0x7Eまたは0xA1~0xDF=1バイト文字
- 0x81~0x9Fまたは0xE0~0xFC=2バイト文字
- それ以外なら制御文字か確かめる
- 文字コード表に該当がなく、制御文字でもないなら「?」とする
という流れでバイト列をStringに変換し、結果用配列に加えていきます。
function convertShiftJisToUtf8(bytes: Uint8Array, codeTable: Map<number, string>): string {
let result = '';
let i = 0;
while (i < bytes.length) {
let byte1 = bytes[i];
// 1バイト文字の判定
if ((byte1 >= 0x20 && byte1 <= 0x7E) || (byte1 >= 0xA1 && byte1 <= 0xDF)) {
let char = codeTable.get(byte1);
result += char || (byte1 >= 0x20 && byte1 <= 0x7E ? String.fromCharCode(byte1) : '?');
i++;
}
// 2バイト文字の判定
else if (((byte1 >= 0x81 && byte1 <= 0x9F) || (byte1 >= 0xE0 && byte1 <= 0xFC)) &&
i + 1 < bytes.length) {
let byte2 = bytes[i + 1];
if ((byte2 >= 0x40 && byte2 <= 0x7E) || (byte2 >= 0x80 && byte2 <= 0xFC)) {
let twoByteValue = (byte1 << 8) | byte2;
let char = codeTable.get(twoByteValue);
result += char || '?';
i += 2;
} else {
result += '?';
i++;
}
}
// 制御文字の処理
else {
if (byte1 === 0x0D) result += '\r';
else if (byte1 === 0x0A) result += '\n';
else if (byte1 === 0x09) result += '\t';
else result += '?';
i++;
}
}
return result;
}CSV行分割
これはオプションですが、Power Automateに戻したあとにさらに操作したいなら、行ごとに分割して配列として返したほうが扱いやすいと思います。
function parseCSVLines(csvString: string): string[] {
let lines: string[] = [];
let currentLine = '';
let inQuotes = false;
let i = 0;
while (i < csvString.length) {
let char = csvString[i];
// セル内改行を見分けるためにダブルクォーテーションで分岐させる
if (char === '"') {
inQuotes = !inQuotes;
currentLine += char;
} else if (!inQuotes && char === '\r' && i + 1 < csvString.length && csvString[i + 1] === '\n') {
// クォーテーション外でCRLFを検出(行区切り)
lines.push(currentLine);
currentLine = '';
i++; // LFもスキップ
} else if (!inQuotes && char === '\n') {
// クォーテーション外でLFを検出(行区切り)
lines.push(currentLine);
currentLine = '';
} else {
// 通常の文字またはクォーテーション内の改行
currentLine += char;
}
i++;
}
// 最後の行を追加
if (currentLine !== '') {
lines.push(currentLine);
}
return lines;
}完成
ここまでの内容をつなげると、Shift_JISを文字列からエンコードされたBase64をUTF-8文字列として返すロジックが完成します。
※コードの全体像はこちら
実際にフローから呼び出して変換してみる
スクリプトが完成したので、Power Automateから呼び出して変換してみましょう。
2000行のShift_JISのCSVファイルをOneDriveに置き、Power Automate経由でOfficeスクリプトに渡します。
今回はテストなので、受け取った結果は何も加工せずにCSVファイルとしてOneDriveに保存しています。
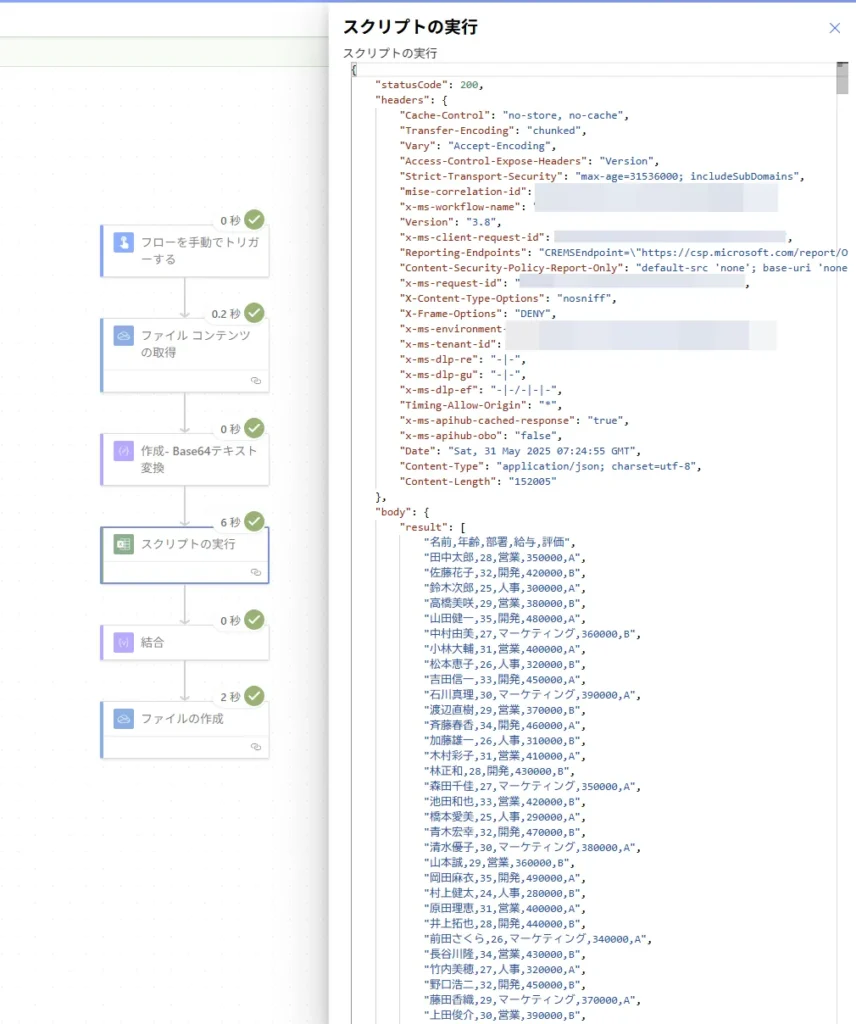
ご覧の通り、きちんとPower Automateで文字として表示されています!
スクリプトの実行時間は約42000字の変換で6秒でした。思った以上に高速ですね。
ダウンロードしてメモ帳で開くと、UTF-8になっていることがわかります。
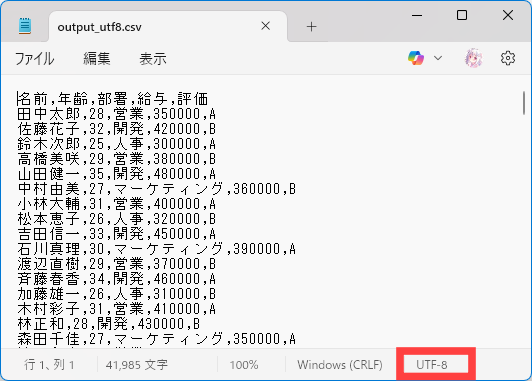
BOMは付けていないので、Excelで開くときちんと文字化けします。文字化けでこんなに安心感を覚えるのは初めてです笑
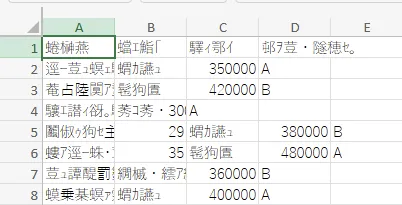
きちんとデータが欠損せずに変換できているのか?
パット見は大丈夫そうですが、本当に誤りがなく変換できているのか気になりますよね。
Pythonで簡易的に判定ロジックを組んだので、元ファイルと変換後ファイルを比較してみます。
import pandas as pd
import os
os.chdir("OneDrive - 個人\ドキュメント\SJIS_変換")
df_sjis = pd.read_csv('テスト用SJISデータ_2000行ver.csv', encoding='shift_jis')
df_utf8 = pd.read_csv('output_utf8.csv', encoding='utf-8')
# データフレームが同じかチェック
if df_sjis.equals(df_utf8):
print('2つのファイルの内容は一致しています')
else:
print('ファイルに差分があります:')
# 形状の比較
print(f"Shape - SJIS: {df_sjis.shape}, UTF-8: {df_utf8.shape}")
# セル単位での比較
comparison = df_sjis.compare(df_utf8)
print(comparison)実行してみると、

一致していますね。ひとまず、複雑な漢字や記号を含んでいなければ大丈夫そうです。
自作文字コード表のデメリット
今回のテスト範囲では正常に変換できていましたが、それでも不安は残ります。
- 文字コード表に誤りがないか検証しきれないため、実務で使うには信頼性に欠ける
- 今回作成した文字コード表生成スクリプトだと、第4水準の漢字が「・」になってしまい、検索対象外になってしまった
- 突き詰めれば実装できるのかもしれないが、今回は断念
まとめ
一応変換には成功したものの、Power Automateではこれくらい無理やりじゃないとShift_JISが扱えないことがわかりました。
何度も書いている通り、このやり方は信頼性に欠けるため実際の業務での使用は非推奨です。
素直にPower Automateプレミアムプランに加入してAzure Functionsを使ったほうが無難じゃないでしょうか。
今回の記事の内容は、「Power Automate単体でShift_JISを扱うのはこれくらい無理やりじゃないとダメなんだな」という学び程度に覚えていただけると幸いです。
「もっと良いやり方を知ってるよ!」や「ここ間違ってるよ!」という方がいましたら、コメント欄で教えていただけると嬉しいです。
ここまでお読みいただいてありがとうございました。








コメント