Power Automateでは残念ながら2つの配列の要素をcontains等で比較することができません。
条件(Condition)で以下のようにすると、左辺の配列の1要素中に、右辺の配列がまるごと含まれていないとtrueになりません。
// 食材リスト
["にんじん", "バナナ", "牛肉", "米", "桃"]
// 果物
["りんご", "バナナ", "いちご", "みかん", "ぶどう", "桃", "オレンジ"]
@contains(outputs('食材リスト'), outputs('果物')) // false// 食材リスト2
[
"にんじん",
["りんご", "バナナ", "いちご", "みかん", "ぶどう", "桃", "オレンジ"],
"牛肉",
"米",
"桃"
]
// 果物
["りんご", "バナナ", "いちご", "みかん", "ぶどう", "桃", "オレンジ"]
@contains(outputs('食材リスト2'), outputs('果物')) // trueApply to Each(それぞれに適用する)やDo untilでループを回せば目的は果たせますが、大変非効率です。
「Swiftのcontains(_:)のように配列に共通要素があればBoolを返してくれる関数があればいいのにな」と思ったので、実現できる方法を考えてみました。
配列の共通部分を抽出できるintersection関数
intersectionというコレクション関数があります。
2つ以上の引数に配列またはオブジェクトを渡し、その共通部分だけの配列またはオブジェクトを返す関数です。
intersection(createArray("a", "b", "c"), createArray("d", "b", "a", "e"), createArray("aa", "abc", "a", "b"))
// 戻り値は["a", "b"]contains関数とは違い、引数に入れた配列やコレクションの要素同士が一致しているか比較することができます。
論理関数ではないので、条件分岐や「アレイのフィルター処理」の条件に使えない
intersectionはBool値を返してくれる関数ではないので、そのまま条件分岐やフィルター条件として使うことができません。
ですが、他の関数と組み合わせることでこの壁も突破できます。
intersection関数とlength関数を組み合わせて条件分岐に対応させる
条件式の入力で、左辺を以下のようにします。
length(intersection(outputs('食材リスト'), outputs('果物')))配列の要素数をintで返してくれるlength関数と組み合わせることで、共通要素があれば1以上、無ければ0が返ってきます。
そして右辺を0にし、「is greater than(より大きい)」で繋ぐことで、共通要素があるときにtrueを返す条件式が完成します。
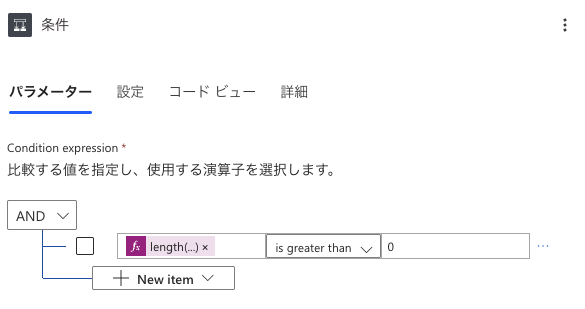
// 食材リスト
["にんじん", "バナナ", "牛肉", "米", "桃"]
// 果物
["りんご", "バナナ", "いちご", "みかん", "ぶどう", "桃", "オレンジ"]
@greater(length(intersection(outputs('食材リスト'), outputs('果物'))), 0) // true実践的な使いどころ
intersection関数が使えると、2次元配列やオブジェクト配列内の配列要素などを条件としたフィルター処理を行うときに、処理時間を大幅に短縮できます。
たとえば、「すべての RSS フィード項目を一覧表示します」アクションで取得した項目のうち、興味のあるカテゴリだけ抽出したいとします。
「すべての RSS フィード項目を一覧表示します」アクションの出力本文は、以下のような構造のJSONです。
JSONのスキーマ(長いので折りたたみ)
{
"type": "array",
"items": {
"type": "object",
"properties": {
"id": {
"type": "string"
},
"title": {
"type": "string"
},
"primaryLink": {
"type": "string"
},
"links": {
"type": "array",
"items": {
"type": "string"
}
},
"updatedOn": {
"type": "string"
},
"publishDate": {
"type": "string"
},
"summary": {
"type": "string"
},
"copyright": {
"type": "string"
},
"categories": {
"type": "array",
"items": {
"type": "string"
}
}
},
"required": [
"id",
"title",
"primaryLink",
"links",
"updatedOn",
"publishDate",
"summary",
"copyright",
"categories"
]
}
}本文がオブジェクト配列であり、categoriesの要素もまた配列です。
この構造でも、intersectionとlengthを合わせて以下のように指定すれば、一発でお気に入りカテゴリの配列と一致するニュースの配列が取得できます。
@greater(length(intersection(item()?['categories'], outputs('作成_-_カテゴリクエリ'))), 0)intersectionとApply to Eachの処理時間比較
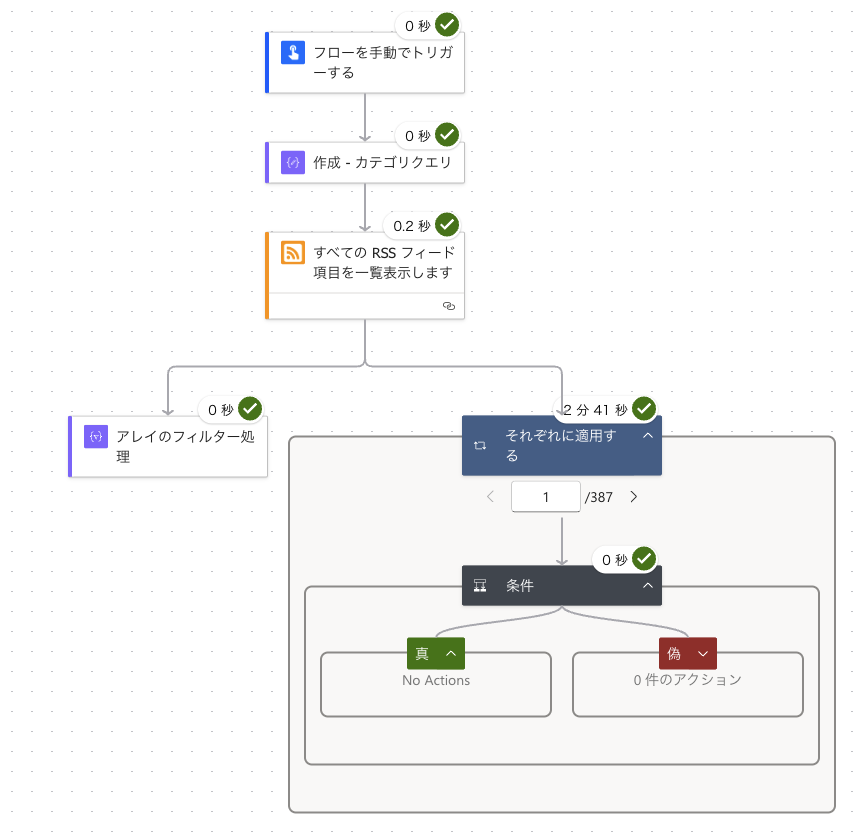
先程の例でintersectionを使わないとすると、
- 記事をApply to Eachでループに掛ける
containの条件分岐(Condition)を作るtrueとなった記事を、ループの外側に作った結果格納用の配列変数に追加する
という処理が必要になります。
試しに387件あるRSSフィードで処理を行わせたところ、intersection&length関数のフィルター処理は0秒で完了したのに対し、Apply to Eachは2分41秒もかかりました。まさに歴然たる差です。
まとめ
Power AutomateのApply to EachやDo untilは非常に処理効率が悪いですし、フローの見通しも悪くなります。
intersection以外にも、Power Automateには便利な関数がたくさんあります。
少しでも多く活用して、効率的なフローを目指しましょう。









コメント